Methodology
|
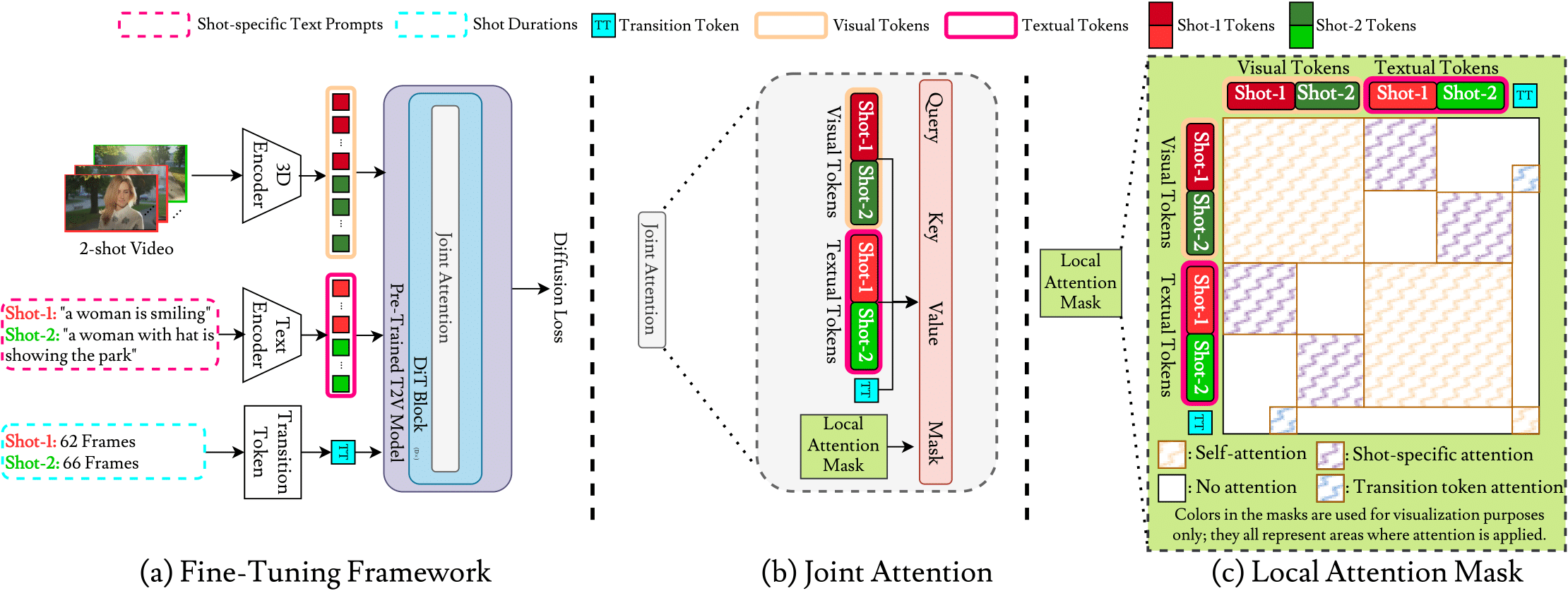
(a) ShotAdapter fine-tunes a pre-trained T2V model by incorporating "transition tokens" (highlighted in light blue). We use n-1 transition tokens, initialized as learnable parameters, alongside an n-shot video with shot-specific prompts, which are fed through the pre-trained T2V model. (b) The model processes the concatenated input token sequence, guided by a "local attention mask" through joint attention layers within DiT blocks. (c) The local attention mask is structured to ensure that transition tokens interact only with the visual frames where transitions occur, while each textual token interacts exclusively with its corresponding visual tokens. |
Dataset Collection
|
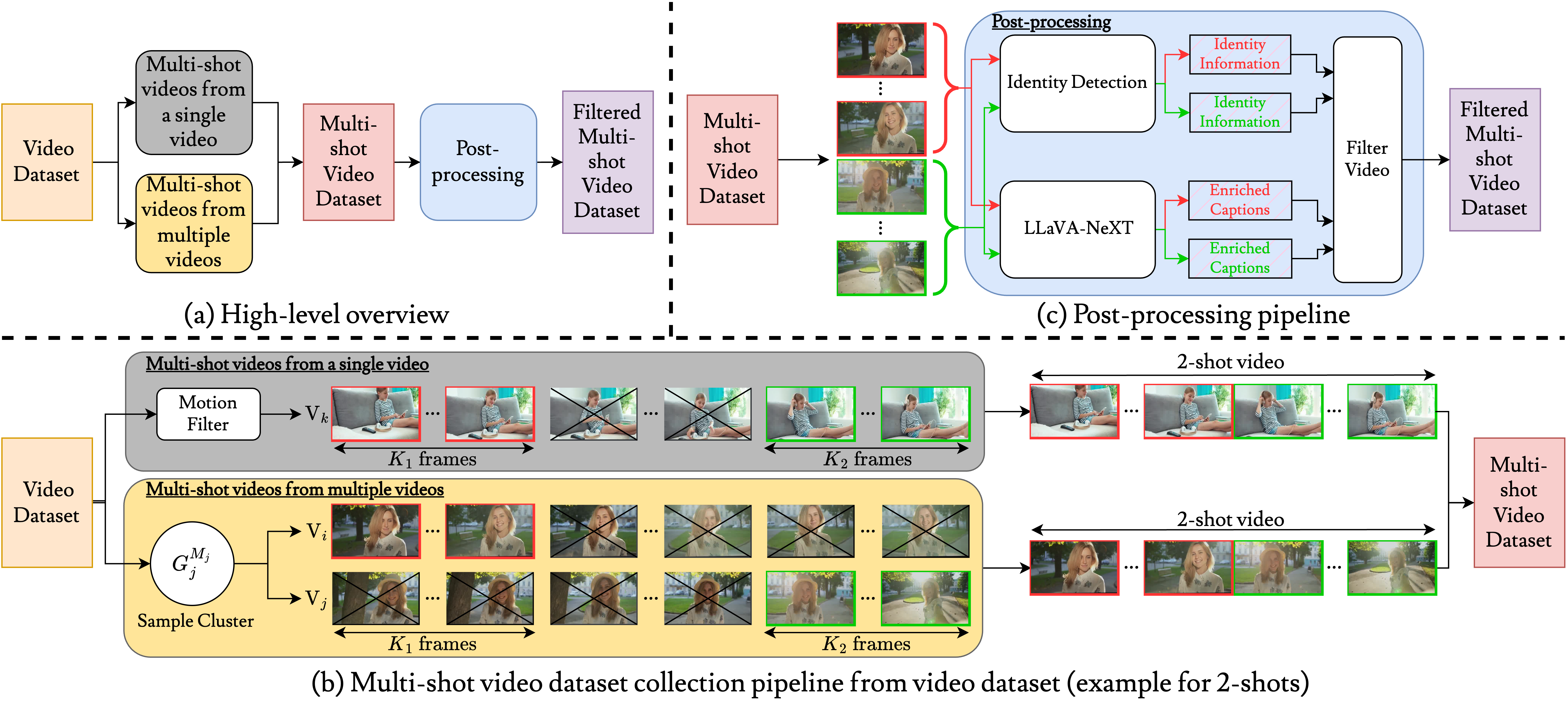
A high-level overview of this pipeline is presented in (a). Our first method (gray box in (b)) samples videos with large motion, randomly splits them into n-shots with varied durations, and concatenates them into multi-shot videos. Our second method (yellow box in (b)) randomly samples n videos from pre-clustered groups containing videos of the same identities and concatenates them to form a multi-shot video. Finally, we post-process (c) the multi-shot videos to ensure identity consistency and obtain shot-specific captions using LLaVA-NeXT. |
Qualitative Results
|
Here we include the complete videos of the examples shown in Figure 1 (teaser) and Figure 5 (qualitative results) of the main paper. We also provide additional multi-shot video and text pairs grouped based on the number of shots being generated. You can find examples where background consistency is maintained across shots (e.g. generated 4-shot video), as well as examples where the background changes (e.g. generated 3-shot video) between shots. Generated 2-, 3-, and 4-Shot Video Results with ShotAdapter (each row displays 1 generated multi-shot video). Each shot is displayed separately in the columns following the first column. For more results please refer to the supplementary material. |
| Generated 2-shot Video | Shot-1 Prompt: "a young girl paints at an easel in her bedroom" | Shot-2 Prompt: "she then reads a comic book in her bed" | ||
|---|---|---|---|---|
Comparison
BibTeX
@inproceedings{kara2025shotadapter,
title={ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models},
author={Ozgur Kara and Krishna Kumar Singh and Feng Liu and Duygu Ceylan and James M. Rehg and Tobias Hinz},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}[1] Oh, G., Jeong, J., Kim, S., Byeon, W., Kim, J., Kim, S., & Kim, S. (2024, September). Mevg: Multi-event video generation with text-to-video models. In European Conference on Computer Vision (pp. 401-418). Cham: Springer Nature Switzerland.
[2] Qiu, H., Xia, M., Zhang, Y., He, Y., Wang, X., Shan, Y., & Liu, Z. (2024). FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling. The Twelfth International Conference on Learning Representations. Retrieved from https://openreview.net/forum?id=ijoqFqSC7p
[3] Wang, F. Y., Chen, W., Song, G., Ye, H. J., Liu, Y., & Li, H. (2023). Gen-l-video: Multi-text to long video generation via temporal co-denoising. arXiv preprint arXiv:2305.18264.
[4] Chen, X., Wang, Y., Zhang, L., Zhuang, S., Ma, X., Yu, J., ... & Liu, Z. (2023, October). Seine: Short-to-long video diffusion model for generative transition and prediction. In The Twelfth International Conference on Learning Representations.
